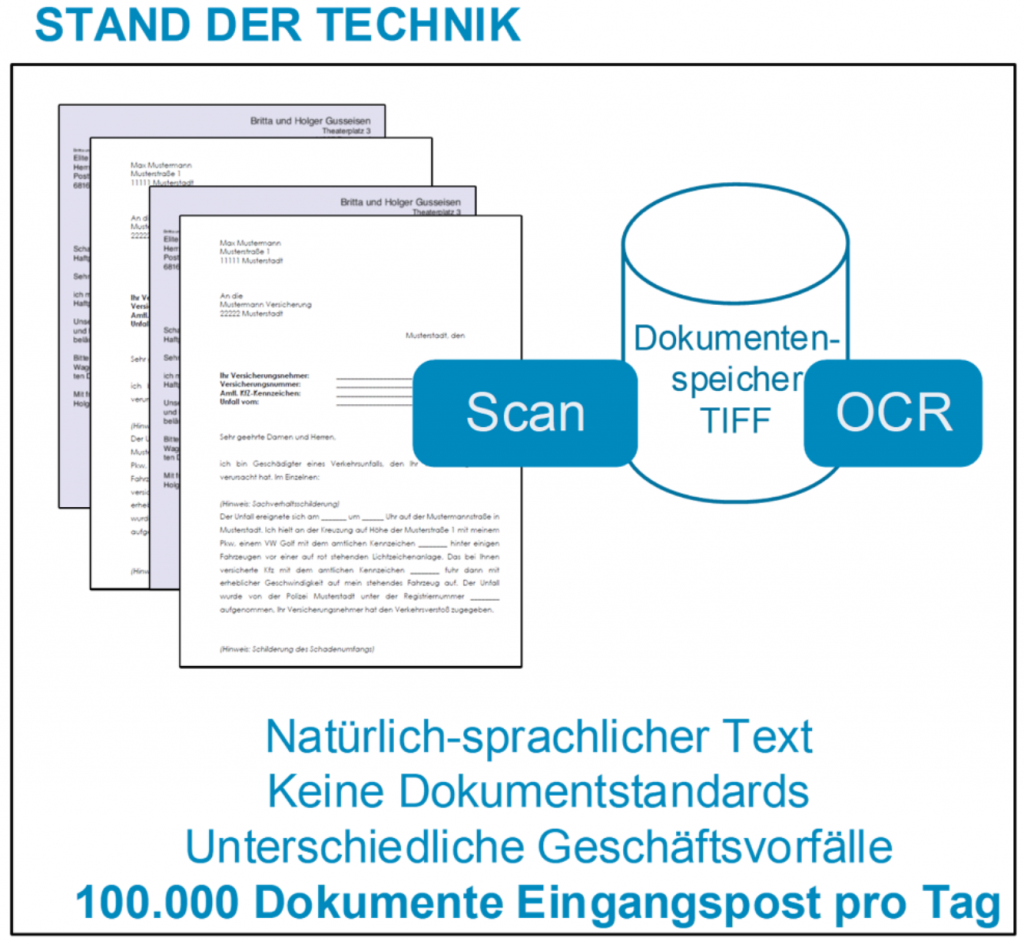
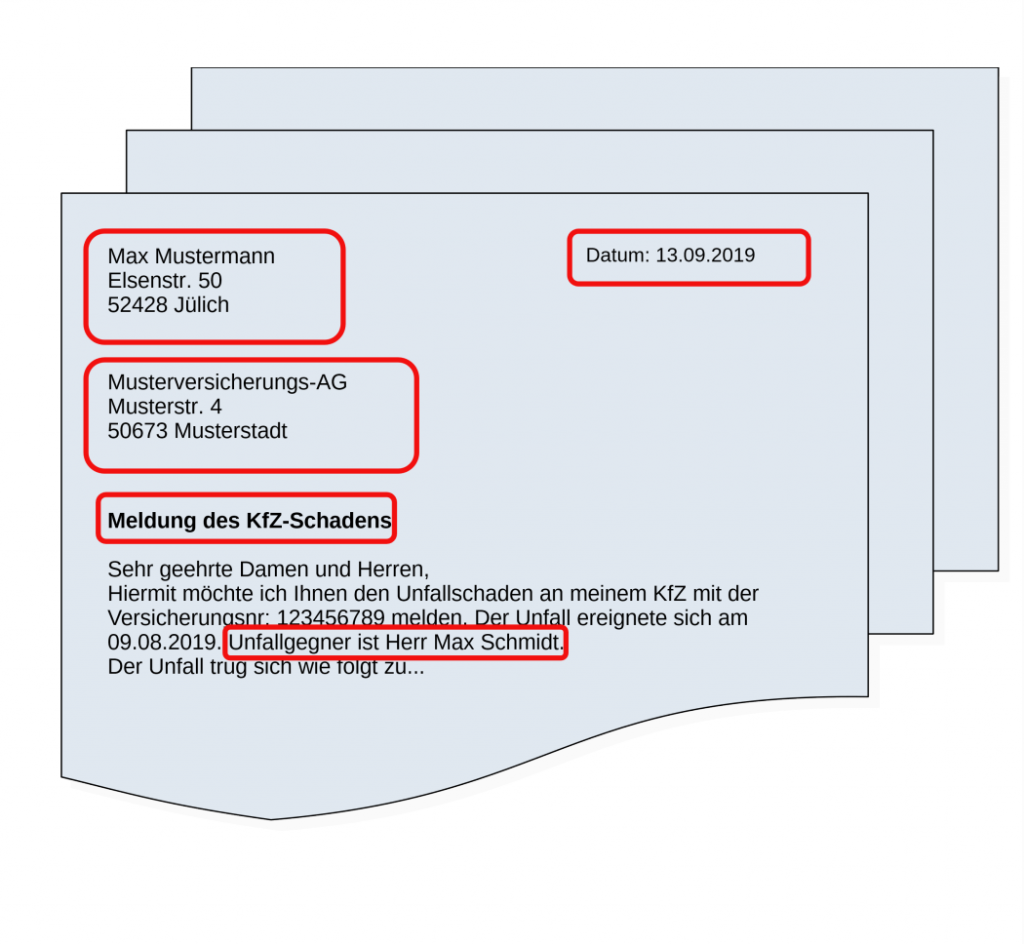
Verschiedenste Unternehmen verarbeiten eine große Zahl formloser Schreiben.
Der automatisierte Scan und eine Texterkennung mittels Optical Character Recognition (OCR) stellen bereits eine gute Vorverarbeitung. Hier ist der Automatisierungsgrad relativ hoch und die Lösungen seit vielen Jahren sehr erfolgreich und robust im Einsatz.
Bislang ist es in den Folgephasen jedoch problematisch diese Dokumente automatisiert semantisch zu verarbeiten. Für die Extraktion relevanter Informationen, Ableitung konkreter Handlungen und somit effektive Entlastung der Sachbearbeiter werden die Optimierungspotentiale nicht gehoben.